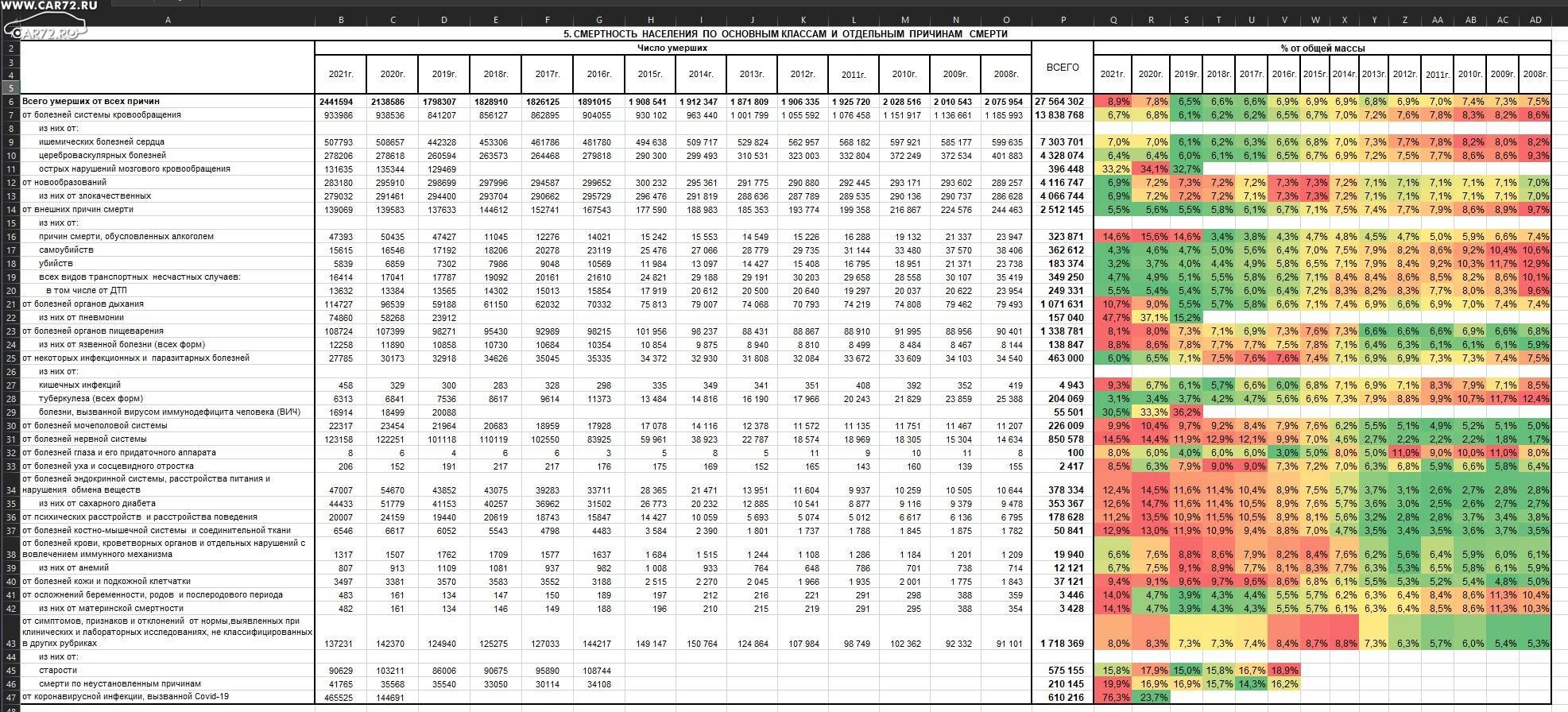
Подозрительность по мнению авторов в том, что выбранная ими пара ферментов разрезает геном SARS-CoV-2 на фрагменты, не превышающие определенной длины. Вот такую меру "искусственности" они придумали. Типа генные инженеры не стали бы использовать слишком длинные фрагменты, им нужны более короткие, но не слишком многочисленные. В идеале несколько фрагментов примерно равной длины тысяч в пять букв, как, действительно, можно обнаружить в некоторых реальных работах по сборке вирусов из кусков. И вот по этому признаку геном SARS-CoV-2 якобы аномален.
Правда по их же данным, существуют заведомо природные коронавирусы, которые еще более аномальны по данному признаку, чем SARS-CoV-2, но это так, мелочи. Не смущает авторов и то, что выбранная комбинация ферментов создает и совсем маленький фрагмент, использование которого ну совсем не целесообразно.
Интересен и выбор конкретной пары ферментов в предложенном анализе. Он продиктован отнюдь не тем, что такая пара ферментов используется генными инженерами чаще всего. А чем? Кто его знает.
Да, указанные ферменты, как и многие другие, иногда используются генными инженерами. Но если взять другие ферменты никакой аномальности скорее всего не получится. Но авторы ведут свои статистические подсчеты таким образом, будто никаких других ферментов не существует. Такой подход называется "cherry-picking", а статистический анализ нуждается в поправке на множественные сравнения, которую авторы целенаправленно опускают (см. мою лекцию "знамения научного апокалипсиса", чтобы узнать об этой распространенной ошибке подробней).
Грубо говоря, если я скажу, что среди моих подписчиков Юль в 5 раза больше, чем Маш, это может кому-то показаться статистической аномалией. Но если окажется, что я перебирал все комбинации имен, как мужских, так и женских, в поисках самого редкого и самого частого, то результат уже не покажется удивительным.
Наконец, абсолютно все участки разрезания генома указанными авторами ферментами встречаются у тех или иных коронавирусов природного происхождения, родственных SARS-CoV-2, обнаруженных в том числе сильно позже. Следствием этого является то, что все они присутствуют в реконструированном геноме общего предка коронавирусов SARS-CoV-1 (атипичная пневмония), SARS-CoV-2 и их родственников (статья: The comparative recency of the proximal ancestors of SARS-CoV-1 and SARS-CoV-2).
То есть каким-то образом предполагаемые генные инженеры при создании SARS-CoV-2 вставляли последовательности узнавания указанных рестриктаз ровно в те места, где они встречаются у природных вирусов, часть которых еще на тот момент и не обнаружили!
Подробней и с картинками весь этот беспредел разбирает в Твиттере биолог Alex Crits-Christoph (acritschristoph). Желающие могут ознакомиться с пруфами у него.
Самое смешное - это реакция на последнее замечание от одного из авторов препринта. "Похоже, что Пекар [автор реконструкции предкового генома группы коронавирусов] прослышали про наш препринт и изобрел "предковый recA геном", фальшивый виртуальный геном, в которым удобным образом есть Bsmbl последовательности [сайты узнавания рестриктаз], с единственной целью обеспечить аргументами Стью и Гансов [непереводимый конспирологический жаргон]".
На что вирусолог Кристиан Андерсон (K_G_Andersen в Твиттере) пошутил, что ученым наверно пришлось вернуться назад во времени, чтобы такое осуществить [реконструкция предкового генома появилась раньше препринта и опирается на геномы природных коронавирусов, которые опубликованы еще раньше другими научными группами].
Замечания к препринту можно продолжать, но на мой взгляд этого достаточно.